...
This ensures that you will get consecutive samples from a single sample sequence, with 'newnsamples' samples for each iteration. I.e. you will get the exact same samples values as if you had shot 'newnsamples' as many camera rays and only 1 sample at each camera hit. In the NewDomainSplit() function, there is a line with the following: newd.sampleid *= newnsamples. That means skipping ahead in the sequence by the splitting branching factor 'newnsamples', thereby ensuring that the combined samples are consecutive and non-overlapping.
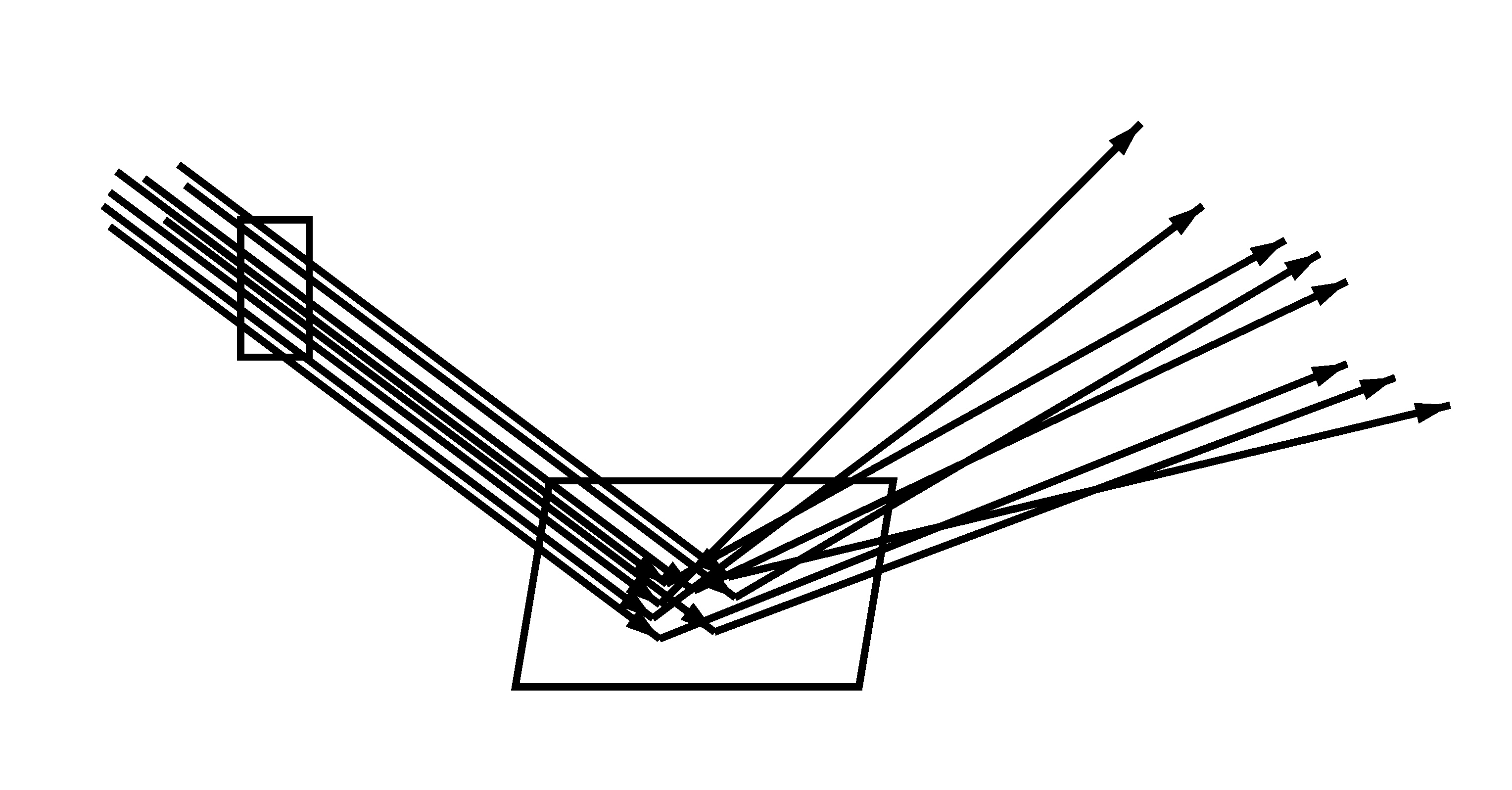
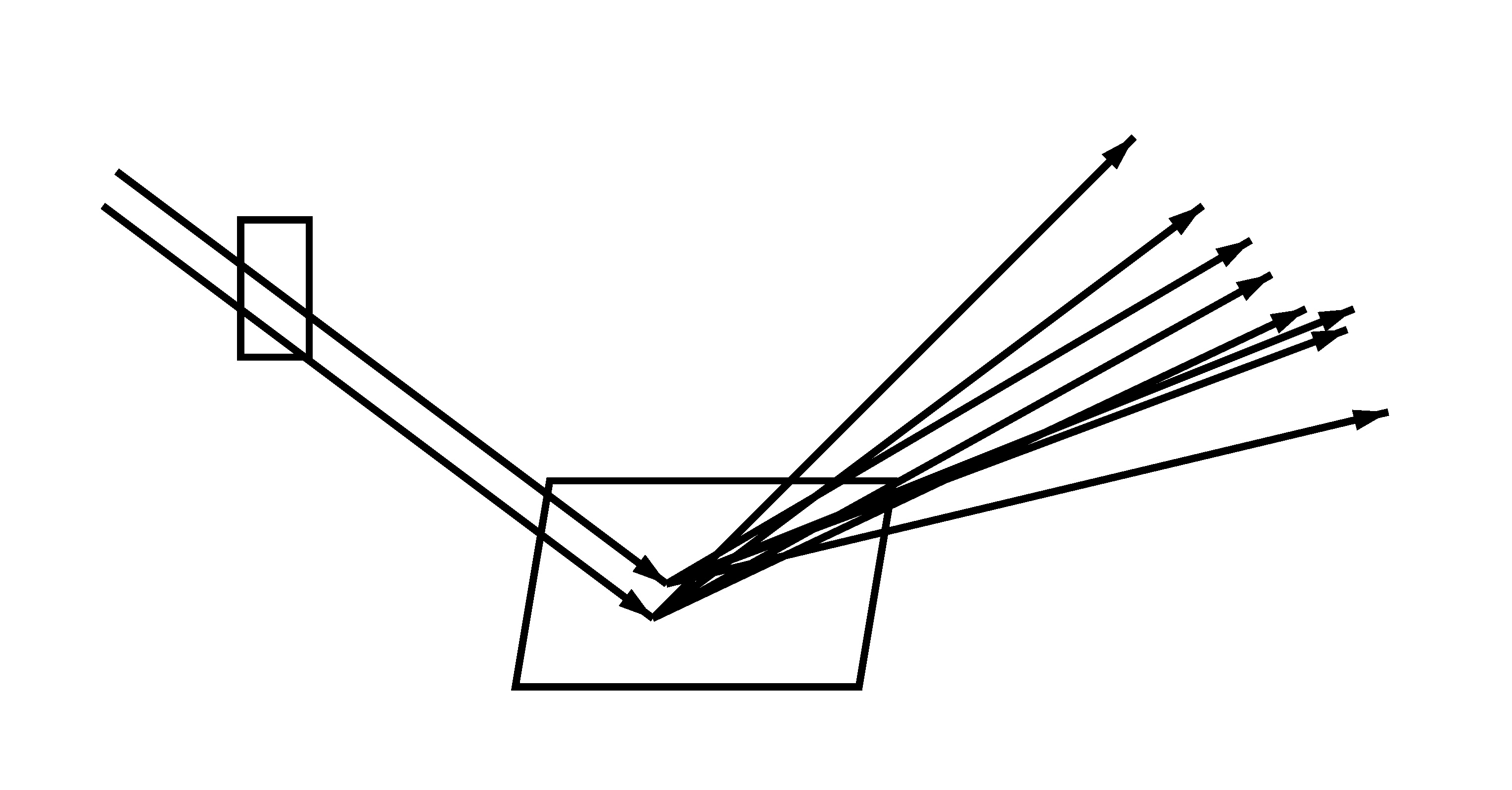
LeftCamera rays through a pixel, hitting a surface and being reflected. Left: no trajectory splitting (8 camera rays with 1 reflection ray each). Right: trajectory splitting (2 camera rays with 4 reflection rays each). Note that the 8 reflection directions are the same in both cases.
...
| Code Block |
|---|
RtFloat2 sample = rng->DrawSample2D(i); float r = radius * sqrt(sample.x); float angle = 2 * M_PI * sample.y; point.x = r * cos(angle); point.y = r * sin(angle); |
An arguably better mapping from the unit square to a disk is Shirley and Chu's concentric mapping. (See Pete Shirley's blog for the most efficient implementation.)
Other common mappings map samples to the surface of a sphere, hemisphere, or cylinder, map samples to directions proportional to a glossy bxdf lobe, and so on.
...
A common – equally good – alternative is called "Shirley remapping". It does not rely on 3D stratification. Instead, get a 2D sample and first use one of the coordinates of the sample to select the sub-domain, and then map the sample within that selected domain (based on the probability) back to the unit square domain. A figure provides a more intuitive explanation:explanation – in this example we choose between two light sources, with 80% chance of selecting the first and 20% chance of selecting the second.
TO DO: Figure of samples before and after remapping?
...
Non-stratified samples similar to e.g. drand48() can be obtained by calling the HashToRandom() function. It computes a repeatable random float between 0 and 1 given two unsigned int inputs, for example patternid and sampleid. The function is repeatable (ie. the same two inputs always give the same output), and has no multi-threaded contention (whereas drand48() has notoriously bad locking, hampering multi-threaded performance). HashToRandom() is located in the RixRNGInline.h include file.
Advanced topic: Details of PMJ table lookup implementation
...
Another practical detail is that even though PMJ sequences theoretically have infinitely many samples, in practice we limit each PMJ table to 4096 samples to keep memory use reasonable. When more than 4096 samples per pixel are used , we get sampleid – i.e. sampleid values higher than 4096 ; we handle this by looking – we look up from the beginning of another PMJ table (also with 4096 samples). So the samples beyond 4096 are still stratified, just not quite as well stratified with respect to the first 4096 samples as if we had had larger tables. For more than 8188 samples per pixel we move to yet another table, and so on. In the unlikely case that more than 196608 samples per pixel are used, we run out of tables – in this case the samples revert to unstratified, uniform (but deterministic) pseudorandom samples generated with the HashToRandom() function described above.
...